基于汉字字频特征实现99.99%准确率的新闻文本分类器(一)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(一)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(二)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(三)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(四)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(五)
基于汉字字频特征实现99.99%准确率的新闻文本分类器(六)
简介
文本分类系列文章,详细并且公开源码的一步一步实现一个新闻文本分类器,准确率搞的夸张一点99.99%并且不是过拟合的99.99%而是具备良好推广性的99%,主要技术特点是采用汉字字频作为特征,和SVM、多层神经网络的应用。
目标
对新闻文本进行二分类,即判断一篇新闻是属于军事类还是非军事类。新闻定义为50个汉字以上的短文,而不是一句话新闻。
99%以上的分类准确率,不陷于局部最优解,能够对语料库里的瑕疵数据进行容错。
具备良好的推广性,即使用训练集以外的海量新闻文本作为测试用例,仍具备不低于98%的分类准确率。
方法
现在自然语言处理做中文文本分类,多是采用词袋模型提取文本特征值。需要切词(分词)去停止符,选取关键词等步骤,对于分词又有多种中文分词器选择,作为特征的关键词选择更是有多种方法。汉字不同于字母文字,字母文字必须由字母组成单词才能表达语义,基于汉字是表义文字而不是表音文字,笔者认为直接采用字频作为文本的特征,比词频更能精确描述文本的内容。所以做了一个尝试,使用文章的汉字字频和常见的算法,希望能得到一个比现有模型更好的文本分类器。使用文本汉字字频,而不是词频有这些优点:无需切词,分词,去停止词,选取关键词等步骤;准确率高。
步骤
这个系列的文章,将采用开门见山的步骤,即
1、用开源的源代码抽取特征数据作为训练/测试集
2、用开源的人工智能算法,对训练集获得一个初步的分类成绩
3、详解源代码,并优化特征数据的处理
4、实现99.99%的分类准确率
5、神秘提升,****加成
好了,说了这么多,让我们开始行动吧。
数据准备
此次分类器的数据,采用搜狗文本分类语料库 http://www.sogou.com/labs/dl/c.html

请下载完整版(107M)的文件 SogouC.tar.gz
但是在笔者尝试下载的时候,发现此文件已经损坏,下载到一个49M的压缩包。只能解压缩出前4万3千个文本文件。百度网盘完整备份,http://pan.baidu.com/s/1qXLo9cS
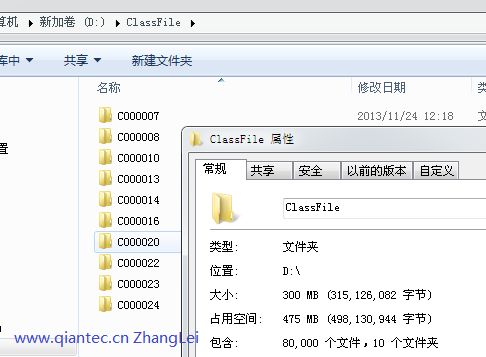
ClassFile.7z,MD5 【1BF6D63389C2AF844A299D0D62621FBA】 将下载的数据压缩文件解压缩,可以看到如图所示,共八万个文本文件,分别属于十个类别。
下节预告
下节,将会提供两个程序的源代码,项目采用C#语言编写,请在计算机上安装好
Visual Studio 2013 社区免费版,当然,Visual Studio 2012或者Visual Studio 2015的社区版/Express桌面版或者更高版本也可以兼容,只需一个即可。
下载地址:https://www.visualstudio.com/zh-cn/downloads/download-visual-studio-vs.aspx
我们会用这些源代码,生成程序并从文本文件中提取字频特征,并一睹99.xx%的风采。
八万分之八的错误,哦,有些挑战。